

1. Googleコンソールへのアクセスと概要
Googleコンソール(Google Cloud Console)は、Google Cloudの管理や設計を行うためのウェブサイトです。
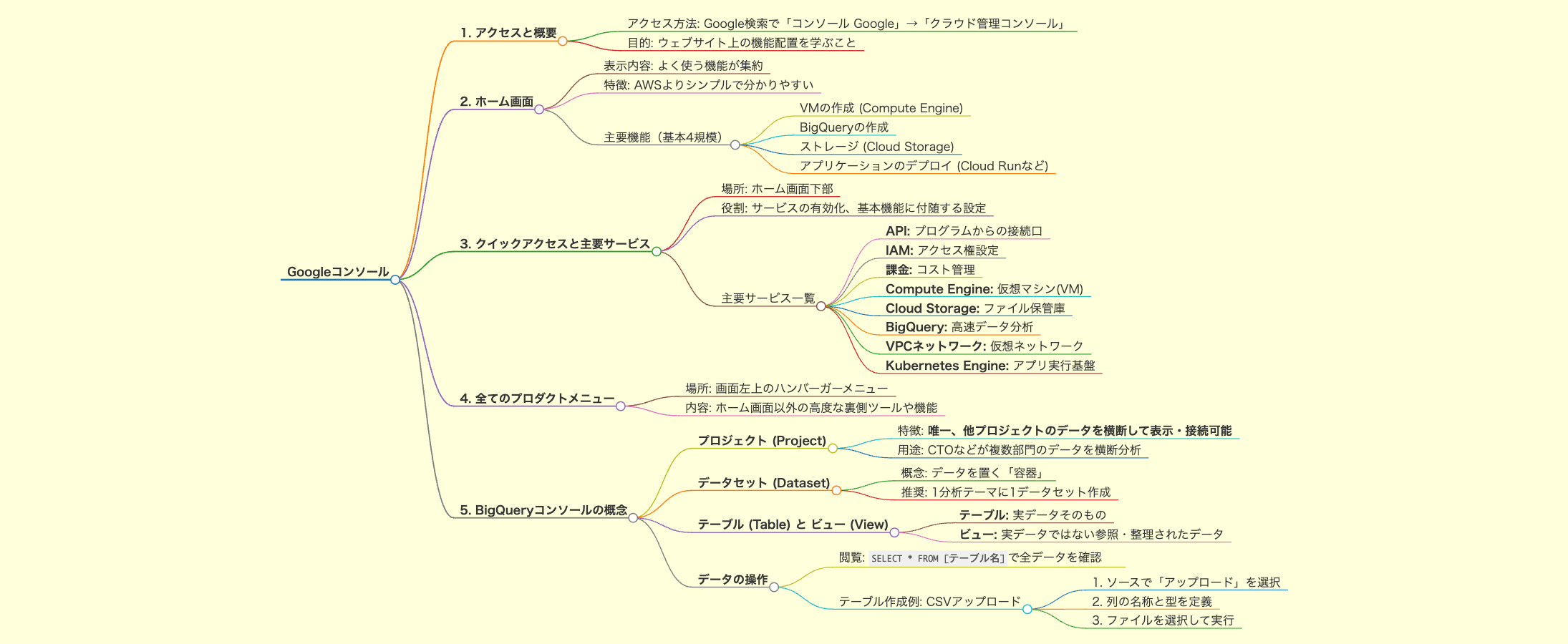
- アクセス方法: Google検索で「コンソール Google」と検索し、「クラウド管理コンソール」(Cloud Console)というリンクからアクセスします。
- 目的: Google Cloudのプロフェッショナルアーキテクチャを学ぶことは、このツールの操作を学ぶことと同義であり、工学的な難しい話ではなく、ウェブサイト上の機能がどこにあるかを把握することが重要と説明されています。
2. ホーム画面
コンソールに初めて入った際に表示されるホーム画面には、基本的によく使う機能が表示されています。
- Google Cloudは、重複するサービスをできる限り作らない方針であり、AWSと比較して親切で分かりやすいとされています。
- 新しいサービスを作成する際、ユーザーが最初に使うであろう情報や機能が集約されています。
- 主な機能:
- VM(仮想マシン)の作成。
- BigQueryの作成。
- アプリケーション(Cloud Runなど)のデプロイ。
- クラウドの利用における基本的な4つの規模(VM、BigQuery、ストレージ、アプリケーションデプロイ)のみが把握できる範囲としてシンプルに提示されています。
3. クイックアクセスと主要サービス
ホーム画面をスクロールした下部には「クイックアクセス」欄があります。これは主に基本の4つの機能に付随する設定や機能が集まる場所です。 Google Cloudの理念に基づき、初期状態では 必要最小限の権限しか付与されていない ため、サービス(例:BigQuery)を利用開始する前にここで明示的に有効化する必要があります。
ここに表示される主要な項目には以下が含まれます:
- API: プログラムからGoogleの各サービスを操作するための「接続口」。
- IAM: 「誰が」「何に」「何をできるか」を設定するセキュリティの要。
- 課金: 利用料金の確認や、予算アラート設定などコスト管理全般を行う。
- Compute Engine: クラウド上でレンタルできる仮想的なコンピュータ(VM)。
- Cloud Storage: あらゆるファイルを保管できる容量無制限のネット上の保管庫。
- BigQuery: 膨大なデータを検索エンジンのような速さで分析できる倉庫。
- VPCネットワーク: クラウド上に、自分たち専用の安全な仮想ネットワークを構築する機能。
- Kubernetes Engine: アプリの起動や管理を全自動で行うための実行基盤。
4.全てのプロダクトのメニュー
画面左上のメニュー(ハンバーガーメニュー)から「全てのプロダクトを表示」をクリックすると、ホーム画面には出てこない裏側のツールや機能が多数確認できます。
- Googleが導入した難易度の高いニーズに対応するためのサービスが徐々に導入されている様子が伺えます。
- Google Cloudエンジニアは、これらの豊富な知識を持つ必要があります。
5. BigQueryコンソールの概念と画面構成
BigQueryの画面に移動すると、以下の重要な概念と画面構成があります。
5-1. プロジェクト (Project)
画面上に表示される名前はプロジェクト名です。BigQueryコンソールの最大の特徴として、BigQueryだけは他のプロジェクトに存在するデータセットを画面内に表示し、プロジェクトをまたいで接続することが可能です。
- これにより、CTOなどの立場にあるユーザーが、異なる部門やグループ会社(それぞれが異なるプロジェクトを持つ)の売上データなどを集計・分析することが容易になります。
5-2. データセット (Dataset)
プロジェクトの下に存在するデータセットは、データを置く「容器」 という概念を持っています。
- 作成と命名: プロジェクトの点々メニューからデータセットを作成できます。
- 目的: 一つの分析テーマに対して一つのデータセットを作成することが推奨されます。
- 例:「2025年全日本サッカー選手のデータ」というテーマに対し、一つのデータセットを作成します。
- データセットを作成する際には、 「リージョン (Region)」 という地理的な観点を選ぶ必要があるという知識が重要です。
- Tableauのように巨大で単一のデータを作るのではなく、BigQueryでは分析の効率化のため、テーマに基づいて地域別、年齢別など細かく分かれたテーブル群をこのデータセット内に用意することが推奨されています。
5-3. テーブル (Table) と ビュー (View)
データセットの配下には、テーブルとビューがあります。
- テーブル: 実際にデータがBigQuery上に保存されている実データです。
- ビュー: 外部から引用してきたデータや、整理・整頓されたデータ、あるいは一時的に保存しておくデータなど、実データではないが利用できる形にしたものです。
5-4. データの閲覧と操作
- データセット内のテーブルやビューを開き、三点リーダーメニューから「新しいタブで開く」を選択すると、クエリを実行できます。
- クエリエディタで
SELECT * FROM [テーブル名](アスタリスク*で全列指定)を実行することで、保存されているデータを確認できます。 - 例:CSVファイルのアップロード(テーブル作成):
- データセットを選択し、「テーブルを作成」をクリックします。
- ソースとして「アップロード」を選択し、CSVファイルを選択します。
- 「フィールドを追加」で、CSVファイルの各列の名称(A, B, C...)と型を定義します。
- これらの設定後、ファイルをアップロードすることで、新しいテーブルが作成されます。