
BrainChain
未来のビジネスを創る、最先端ブログシステム
ChatGPTとの連携で瞬時に調査内容や質問の答えをブログとして保存・共有して、MindMap & 自動タグ作成して視覚的な情報整理ができるテックブログシステム。
Google Cloud
 蒸気機関からAIエージェントへ:Google Cloud Next Tokyo 2026が示した「生産性爆発」への処方箋
蒸気機関からAIエージェントへ:Google Cloud Next Tokyo 2026が示した「生産性爆発」への処方箋 Google Cloud Next Tokyo 2026をDay1 Keynoteでは、AIを活用した「生産性爆発」の実現方法を解説。チャットボットから現場分散型のAIエージェントへの転換、シャドウAIの公認化、損害保険ジャパンやスクウェア・エニックスの事例から見る業務の消去やマルチモーダル活用など、日本企業が取り組むべき実践的アプローチをまとめています。

AI
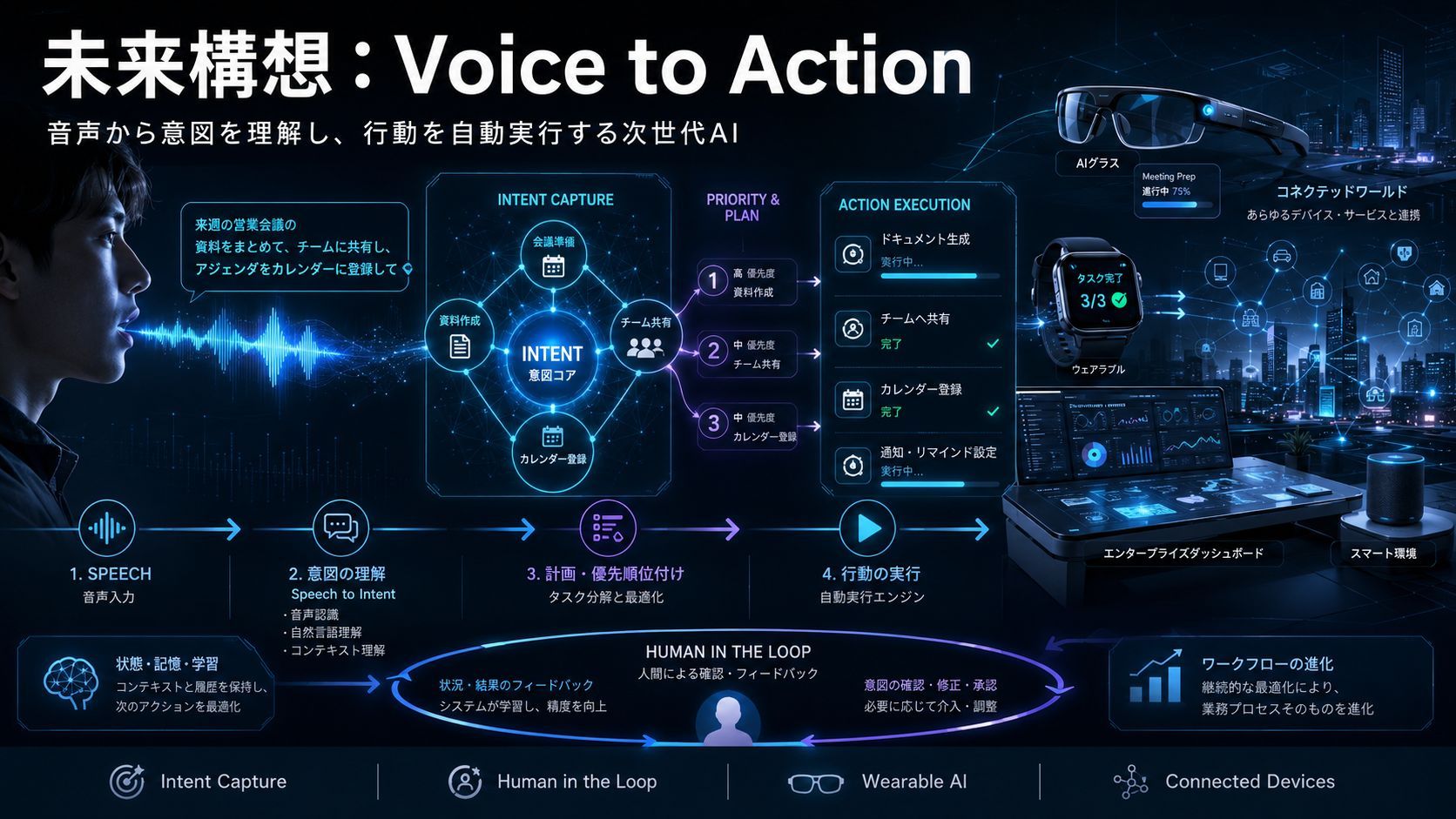 未来構想:Voice to Action(音声による行動実行)の技術理論と産業変革
未来構想:Voice to Action(音声による行動実行)の技術理論と産業変革 音声を単なる文字変換と捉える「Speech to Text」から脱却し、ユーザーの意図を汲み取り自律的にアクションを実行する「Voice to Action」理論を提唱。ハードウェアの再定義や開発者の役割転換、AI産業の未来像について論じる。
AI
 【2026年最新】AI実運用の現在地:Task CrossoverとマルチエージェントによるAI駆動開発
【2026年最新】AI実運用の現在地:Task CrossoverとマルチエージェントによるAI駆動開発 2026年、AI活用はPoCを終え実運用フェーズへ移行しました。職種の壁を越えて業務を完結させる「Task Crossover」が加速し、非エンジニアによる開発も一般化しています。また、マルチエージェントによるAI駆動開発が劇的な生産性向上をもたらしており、日立や損保ジャパン等の成功事例も増加中です。本記事では、AI前提の組織設計やナレッジ管理など、最新の実運用トレンドと成功の鍵を解説します。

AI
 NVIDIAが主導する「Open Secure AI Alliance」発足:AIセキュリティの未来を切り拓くオープンエコシステム
NVIDIAが主導する「Open Secure AI Alliance」発足:AIセキュリティの未来を切り拓くオープンエコシステム NVIDIAは、AIの安全性向上を目指し、MicrosoftやDatabricks等40以上の組織と「Open Secure AI Alliance」を設立しました。AIセキュリティを共有すべき「防御資産」と捉え、オープンな技術開発や標準フレームワークの共有を推進します。GitHubで公開された監査ツール「NOOA」など、具体的な成果を通じてAIエージェントの脆弱性に対応し、グローバルな防御能力の最大化を目指す取り組みです。

AI
 2026年のAI地政学:米国vs中国の対立とマルチモデル戦略の重要性
2026年のAI地政学:米国vs中国の対立とマルチモデル戦略の重要性 2026年現在のAI開発競争は、米国の技術的優位と中国の圧倒的なコスト優位・オープンソース戦略が激突する局面を迎えています。中国勢は制裁下で培った効率化技術で台頭し、米国は安全保障や知的財産の観点から警戒を強めています。企業は機密性やコストのバランスを考慮し、米国のフロンティアモデルと中国のオープンモデルを適材適所で使い分ける「マルチモデル戦略」の構築が不可欠となっています。
Google Cloud
 Googleが明かすAI活用の現在地:仕事の「代替」ではなく「協業」を加速させるツールとしての役割
Googleが明かすAI活用の現在地:仕事の「代替」ではなく「協業」を加速させるツールとしての役割 Googleの研究データに基づき、AIが職場で「人間の代替」ではなく「生産性を高める協力ツール」として機能している実態を解説します。現在は特定のタスクを補助する「浅い協業」の段階にあり、特に非定型な認知分析業務で高い効果を発揮しています。事務職だけでなく技術職でも専門性を拡張する道具として活用が進む中、AIをいかに使いこなし自身の専門性をブーストさせるかが今後のキャリアの鍵となります。
Google Cloud
 Firebase連携iOSアプリをTestFlightへビルド・デプロイする手順
Firebase連携iOSアプリをTestFlightへビルド・デプロイする手順 Firebaseを連携したiOSアプリをTestFlightへビルド・デプロイするための具体的な手順を解説します。Firebaseコンソールでの設定からXcodeでのアーカイブ、TestFlightへのアップロードまで、開発現場で役立つ一連の流れを網羅。Apple Developerアカウントの管理や設定ファイルの配置など、スムーズな検証環境構築に必要なポイントを簡潔にまとめています。
AI
 AI時代のエンジニア報酬二極化:下流工程5割安の衝撃と生き残り戦略
AI時代のエンジニア報酬二極化:下流工程5割安の衝撃と生き残り戦略 生成AIの普及により、ITエンジニアの報酬が二極化しています。コーディングなどの下流工程は単価が5割低下する一方、要件定義やPMなどの上流工程は需要が急増し単価も上昇傾向にあります。本記事では、最新の調査データを基に、AIに代替されない「課題解決型エンジニア」へとシフトするための3つのポイントを解説。変化をチャンスに変えるためのキャリア戦略を提案します。