

従来のデータ処理アーキテクチャは、根本的な課題を抱えていました。しかし、FirebaseやSuperbaseのような最新技術は、かつて必須とされた「ETL処理」そのものを不要にし、データ基盤のあり方を大きく変えようとしています。
本記事では、従来のデータベースが抱えていた問題点から、ETL不要論に至るまでの技術的な流れを解説します。
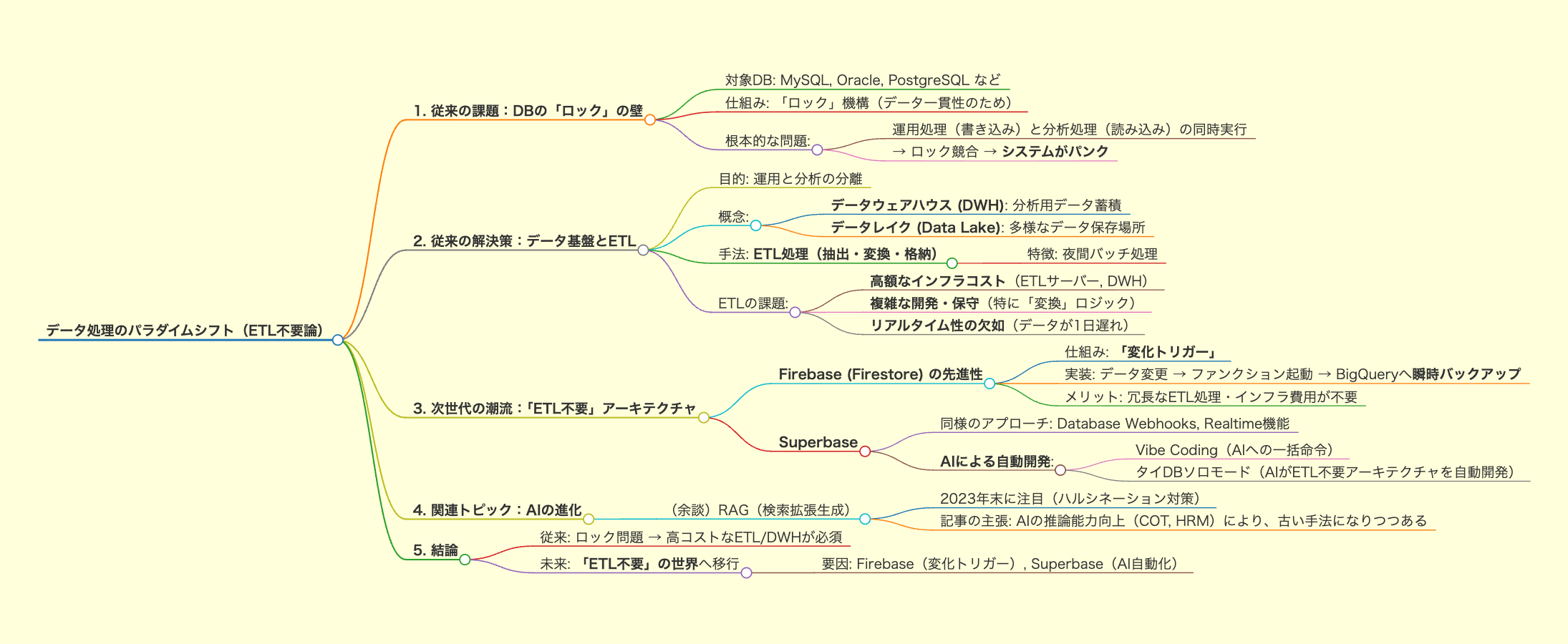
1. 従来のデータベースが抱えた「ロック」の壁
従来のデータ処理において、中核となるのはMySQL、Oracle、PostgreSQLといったデータベース(DB)ソフトウェアでした。
これらのデータベースはウェブページと直接連携し、ユーザーがフォーム入力したデータなどを保存する役割を担います。しかし、そこには大きな制約がありました。それが「ロック(Lock)」機構です。
- ロックとは?: データの一貫性を保つため、誰かがデータの挿入(Insert)、更新(Update)、削除(Delete)を行う瞬間、そのテーブルが一時的にロックされます。
- 根本的な課題: このロック機構のため、ウェブページからの書き込み(運用処理)と、ダッシュボードなどでのデータ読み込み(分析処理)を同時に行うと、システムがパンクしてしまいます。
2. 課題解決策としての「データ基盤」とETL
この「運用と分析の同時処理ができない」という問題を回避するために、「データウェアハウス(DWH)」や「データレイク」といったデータ基盤の概念が生まれました。
データウェアハウス(DWH)
DWHは、分析やレポート作成のために過去のデータを蓄積するシステムです。 最大の特徴は、運用DBへの負荷を避けるため、 ETL処理(Extract: 抽出、Transform: 変換、Load: 格納) と呼ばれるプロセスを用いる点です。
- ETL処理:
- ウェブサイトと連携する運用DBから、利用者が少ない夜間などにデータを 抽出(Extract) します。
- 分析しやすいようデータを 変換(Transform) ・構造化し直します。
- 分析用の別データベースにデータを 格納(Load) します。
データレイク(Data Lake)
データレイクは、DWHの仕組みの中で、ETL処理後のデータを保存する「場所」の概念です。ファイル、メディア、バイナリデータなど、様々な種類のデータを「湖」のようにそのままの形で置いておく貯蔵庫を指します。
ETLの課題:コストとリアルタイム性の欠如
この従来型アーキテクチャは、運用と分析の分離には成功しましたが、以下の課題を抱えていました。
- 高額なインフラコスト: ETL処理を実行するための専用サーバーや、DWHの維持・運用に多額のコストが発生しました。
- 複雑な開発・保守: ETL処理(特に「T=変換」ロジック)の構築とメンテナンスは複雑で、専門的なスキルが必要でした。
- リアルタイム性の欠如: データは1日1回(夜間バッチ)しか更新されないため、分析者は常に「昨日」のデータを見ることになり、即時的な意思決定が困難でした。
3. 次世代の潮流:「ETL不要」アーキテクチャの登場
最先端の技術動向は、この高額で複雑なETL処理を過去のものとする「 ETL不要 」のアーキテクチャへと移行しています。
Firebase (Firestore) が持つ先進性
Google Firebase(Firestore)の技術は、まさにこの「ETL不要」を実現する先進的なアーキテクチャです。
従来のDWHやETLインフラが不要となる理由は、その「 変化トリガー 」の仕組みにあります。
- 瞬時のバックアップ: Firestoreは、データベース内でデータが変化したことをトリガーとして、ファンクション(機能)を自動的に起動できます。
- 具体的な流れ: この仕組みを使い、Firestoreのデータが変更された瞬間にファンクションが起動し、分析用の BigQueryに瞬時にデータをバックアップ します。
これにより、わざわざ夜間にデータを吸い上げ、変換・格納するといった冗長なETL処理が一切不要となり、関連するインフラ費用も削減できるのです。
同様のアプローチは、Superbase(Database WebhooksやRealtime機能)など他のモダンなBaaS (Backend as a Service) でも可能になっており、この「リアルタイムETL」が次世代の標準となりつつあります。
AIが「ETL不要」の開発を自動化する
AIの推論能力が強くなる未来では、人間が複雑なワークフローを組む必要がなくなります。 この流れを汲むのが、先進的なサービスである Superbase です。
Superbaseは、Vibe Coding(AIに一発で命令し、すべてを任せる開発手法)と連携し、「タイDBソロモード(Try AIのソロモード)」を通じて、 AIがゼロから「ETLが不要なアーキテクチャ」を自動で開発してくれる 機能を提供しています。
4. AIの進化と未来のデータ基盤
この「ETL不要」の流れは、AI技術の急速な進化とも連動しています。
(余談)RAGとAIの進化
2023年末頃、AIのハルシネーション(嘘)対策として RAG(検索拡張生成) が注目されました。これは、自然言語をベクトルデータ(採点)に変換してDBに保存し、質問のベクトルと距離が近いデータを検索して回答を生成する技術です。
しかし、AIモデルの推論能力自体が向上(COT: 思考の連鎖、HRM: 階層的推論モデルなど)したことで、RAGはすでに古い手法となりつつあります。
まとめ
従来のデータ処理は、DBのロック問題を回避するためにDWHと高額なETL処理を必要としていました。
しかし、Firebase (Firestore) の「変化トリガー」による瞬時バックアップや、SuperbaseとVibe Codingが示すAIによる自動開発は、データ基盤のあり方を根本から変えています。
未来は、複雑なETL処理や高額なインフラ費用から解放された、「ETL不要」の世界へと確実に移行しつつあります。