

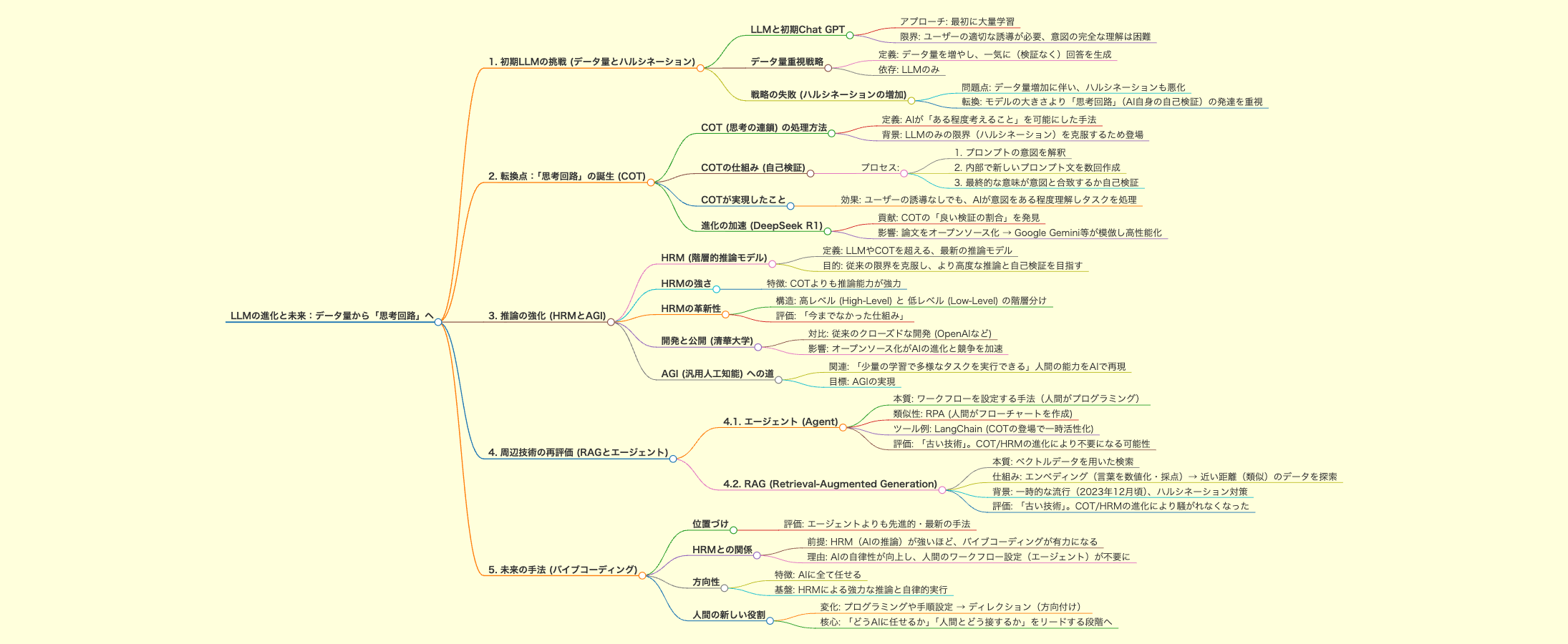
大規模言語モデル(LLM)の進化は、単なるデータ量の増加から、AI自身が「考える」能力、すなわち「思考回路」の発展へと急速にシフトしています。
本記事では、初期のLLMが直面した課題から、それを克服したCOT(思考の連鎖)、さらに強力な推論能力を持つHRM(階層的推論モデル)への進化、そしてRAGやエージェントといった周辺技術が現在どのような位置づけにあるのかを解説します。
最後に、AIの進化がもたらす次世代の開発手法「バイブコーディング」について考察します。
1. 初期LLMの挑戦 — データ量とハルシネーション
LLM(大規模言語モデル)と初期のChat GPT
LLM(大規模学習モデル)は、最初のChat GPTが採用した手段でした。このアプローチは、モデルに大量学習させてから処理を行うというイメージに基づいています。
2023年に登場した最初のChat GPTは、当時の基準では、現在のモデルのように「全てを綺麗に生成してくれるわけではない」とされています。
初期のChat GPTは、私たちが適切に質問すれば回答は返してくれましたが、ユーザー側が適切に誘導しなければ、AIは「意図の全て」を汲み取ってくれるわけではありませんでした。
データ量重視戦略:「回答」の即時生成
LLMが最初に採用していたAIの方向性は、主にデータ量の拡大に焦点を当てていました。
- 初期戦略の定義: AIの方向性は、従来LLMのみに依存しており、「とりあえずデータ量を増やして、一気に回答を出す」という点にのみ注力していました。これは、最初のChatGPTが用いていた手段でもありました。
- 検証なき回答: この「一気に回答を出す」とは、学習したデータに基づいて、検証を行わずにすぐに回答を生成することを意味します。初期のモデルは、質問に対して回答はするものの、ユーザーが適切に誘導しないと、裏の意味まで考えて処理してくれるわけではありませんでした。
データ量増大戦略の失敗:「幻覚(ハルシネーション)」の増加
しかし、データ量を増やし続けるという戦略は、問題を引き起こしました。
- 幻覚(ハルシネーション)の増加: データ量増加の戦略を継続しようとした試みは失敗したとされています。なぜなら、モデルに投入するデータが増えれば増えるほど、かえって幻覚(ハルシネーションや不正確な出力)がさらに悪化するという問題が発生したからです。
- 研究方向性の変化: この問題の結果、研究のアプローチが大きく変わりました。単にモデルを大きくすることには意味がなくなり、代わりに、AIが人間に出力するまでに、AIがまず自分自身を検証するという「思考回路」の発達に焦点が移りました。
2. 転換点 — 「思考回路」の誕生 (COT)
データ量重視の戦略が限界を迎え、研究の焦点はAI自身の「思考回路」へと移りました。その最初の大きなブレイクスルーがCOT(Chain of Thought)です。
COT(思考の連鎖)という処理方法
COT(Chain of Thought、思考の連鎖)は、単なる新しい技術というだけでなく、LLMの発展の方向性を大きく転換させた、より大きな文脈を持つ処理方法として説明されています。
COTは「思考の連鎖」と呼ばれる新しい手法、あるいはモデルであり、AIが「考えること」を可能にした手法です。
従来のLLMとの違いと出現の背景 初期のChat GPT(2023年頃)は、利用者がしっかりと質問を誘導しなければ、意図の全てを理解し、回答を提供するわけではありませんでした。当時のAI研究は、単にデータ量を増やして巨大なモデルを構築すれば、一気に答えを提供できるというLLMのみの方向性に注力されていました。しかし、このデータ量を増やしすぎると、かえって幻覚(ハルシネーション)がさらに悪化するという問題が生じました。
この問題を解決し、AIの性能を飛躍的に向上させるために登場したのがCOTです。
COTの仕組み:新しいプロンプト文を数回作り自己検証
COTの文脈において、「新しいプロンプト文を数回作り自己検証」という概念は、AIがより高度な推論や思考プロセスを実行可能にするための根本的な仕組みを指します。
- 思考の連鎖としてのCOTの定義: COTは、従来のモデルが適切に誘導しないと質問の意図を全て理解できなかった課題を克服するため、「思考の連鎖」という新しい手順として開発されました。
- 自己検証の具体的な仕組み: AIが「考える」とは、具体的には私たちのプロンプトに対し、そのプロンプトが何を意図しているのかをAIが解釈し、自分自身で新しいプロンプト文を数回作成することを指します。
- 検証の重要性: そして、プロンプト文を数回作成した後、最終的なプロンプト文の意味が意図に合っているかどうかをAI自身で検証する仕組みが組み込まれています。この検証の仕組みこそが、モデルが正確な回答を生成できるようになった要因の一つです。
COTが実現した「AIが考えること」
「考える」ことの実態としてのCOTの仕組み AIが「考える」とは、人間に近い思考そのものではなく、以下のような自己検証の仕組みを指します。
- 内部的なプロンプト生成: ユーザーからのプロンプトに対して、AIが「このプロンプトはこういう意図だ」と解釈し、数回の新しいプロンプト文を自ら作成する。
- 自己検証: 作成された複数のプロンプト文が、最終的に意図する意味に合致するかどうかをAI自身が検証する仕組み。
- 効果: ユーザーが細かく誘導しなくても、AIが意図をある程度理解し、ほとんどのタスクを処理して出力できるようになったのが、このCOTモデルの力です。
DeepSeek R1の論文公開が進化を加速
COTの文脈において、DeepSeek R1の研究成果(論文)の公開は、AIの進化を加速させました。
DeepSeek R1は、このCOTモデルの性能を最大化する鍵となる要素を発見し、それを広く公開することで、AI業界の進化を決定的に加速させました。
- 検証の割合の発見: COTの仕組みにおいて、検証を行う回数や割合が重要となりますが、中国のDeepSeekのチームが、この 「良い割合」 を模索できたとされています。
- 論文の公開による加速: DeepSeekは、その研究成果であるDeepSeek R1の論文を、 無料(オープンソース)で シェアしました。この動きは、当時のOpenAI(Chat GPT)が、手法やソースコードをクローズド(非公開)にしていた状況とは一線を画しています。
- 市場競争の促進: DeepSeekが技術を公開したことにより、Googleがすぐにそれを模倣することができ、Geminiが 一気に 高性能になったとされています。
3. 推論の強化 — HRMとAGIへの道
COTによって「思考回路」を獲得したAIは、さらに強力な推論能力を持つ「HRM」へと進化しています。これは、AGI(汎用人工知能)の実現に向けた大きな一歩と見なされています。
HRM (Hierarchical Reasoning Model):階層的な推論モデル
階層的な推論モデルであるHRM(Hierarchical Reasoning Model)は、AIの推論能力がLLMやCOTを超えて進化している、研究の方向性の転換点において登場した最新のモデルです。
HRMは、従来のAI開発の限界を克服し、AIがより高度な推論と自己検証能力を持つことを目指すという文脈で登場しました。
HRMの強さ:COTの上にさらに推論が強い
HRM(Hierarchical Reasoning Model:階層的推論モデル)は、COT(Chain of Thought:思考の連鎖)の上にさらに 推論 が強いモデルです。
AI推論モデルは、初期のLLMが幻覚(ハルシネーション)の増大という問題を引き起こしたため、AIが自分自身を検証する「思考回路」の発展へと移行しました。
- COT(思考の連鎖)の役割: COTはこの思考回路の初期の発展を代表するものです。
- HRMの推論能力: HRMは、この思考回路の進化のさらなる発展として位置づけられています。ソースは、HRMを「 推論 が強いモデル」と明確に定義しており、その強さを「COT の上にさらに推論が強いモデルです」「つまり COT よりは強い」と述べています。
HRMの革新性:ハイレベルとローレベルの階層分け
HRM(Hierarchical Reasoning Model、階層的推論モデル)の「階層的」たる所以は、高レベル(High-Level)と低レベル(Low-Level) が階層を分けられている点にあります。
- 革新的な仕組み: ソースによると、この高レベルと低レベルに階層を分けるという仕組みは、「今までなかった仕組み」 であると強調されています。
- 機能的な特徴: この新しい階層分けによって、HRMは 推論 が非常に強いモデルとして機能します。
清華大学による開発とパブリック/オープンソース化
HRMが注目される最大の理由は、中国のトップ大学である清華大学がこのモデルを開発し、パブリック/オープンソース化したという点にあります。
この行動は、現在の主要なAI業界の動向とは一線を画すものです。
- 既存の閉鎖的な環境との対比: Chat GPT(OpenAI)、GoogleのGemini、AnthropicのClaudeの多くは、ソースコードや具体的な開発手法を クローズド(非公開)にしています。
- オープンソース化がもたらす革新: HRMがパブリック/オープンソース化されたことにより、AIの進化の速度が加速し、市場の競争が活発化することが期待されます。
HRMが目指すAGI(汎用人工知能)の実現
HRM(Hierarchical Reasoning Model:階層的推論モデル)は、AGI(汎用人工知能)の実現を目指す動きと直接的に関連しています。
ソースは、HRMの開発が、従来のAIが抱えていた限界を超え、真の汎用性を持つAI、すなわちAGIの実現を視野に入れたものであることを明確に示しています。
- 人間の能力の再現: HRMは、 「人間が少量の学習で多様な思考やタスクを実行できる」 という能力を、まさにAIで実現させようとしている動きであると説明されています。
- AGIとの直接的な関連: この人間の学習・推論能力の再現を目指す動きこそが、AGI(汎用人工知能) であると明確に示されています。
4. 周辺技術の再評価 — RAGとエージェント
AIモデル自身の「思考回路」が進化する一方で、これまで注目されてきたRAGやエージェントといった技術は、その役割を終えつつある「古い技術」として再評価されています。
4.1. エージェント (Agent)
エージェントの本質:ワークフローを設定する手法
LLMのより大きな文脈において、「エージェント(Agent)」がワークフローを設定する手法として、ソースはそれが古くなった技術であり、人間のプログラミングに依存しているという点を指摘しています。
- 具体的な手法: これは、「こういう言葉があったら、まずはエージェントとしてこれを人間でプログラミングして、これをこういう風に処理する。処理したら次のプログラムにバトンタッチする」という流れを人間が定義することです。
- 本質はフローチャート作成: 要するに、人間がこのフローチャートを書くだけの手法であり、昔の RPA(Robotic Process Automation)と同様である と説明されています。
LangChainなどのツールとCOTの関係
LangChainは、このエージェント開発手段の具体例として言及されています。
- LangChain=エージェント開発: LangChainには、メモリーチェーンやSQLチェーンなどが含まれます。
- COTモードによるLangChainの活性化: LangChainのような「チェーン」の概念は以前から存在していましたが、その効果が飛躍的に高まったのは、基盤となるLLMエンジンが進化し、「思考回路」(COT)を持ったことによります。COTモードによって、LLMエンジン自身が「どのチェーンを使えばいいか」ということをある程度コントロールできるようになったのです。
エージェントは「古い技術」になる
現在世の中で「エージェント」として騒がれている開発手法やモデルは、実は新しい技術ではなく、その実態は古いと指摘されています。
エージェント開発手法が「古い技術」となる最大の理由は、LLMの基礎となるAIモデル自体の推論能力が飛躍的に進化しているためです。COT(思考の連鎖)やHRM(階層的推論モデル)といった技術の登場により、AIモデルは自分自身を検証する「思考回路」を持つようになりました。
結果として、モデル自身が考えられるようになるため、「人間がこのフローチャートを書くだけ」で成立していたエージェントの開発自身が不要になると予測されています。
4.2. RAG (Retrieval-Augmented Generation)
RAGの本質:ベクトルデータを用いた検索
RAG (Retrieval-Augmented Generation、検索拡張生成) は、ハルシネーション対策として一時的に注目された、比較的単純な情報検索技術です。
RAGの本質は、AIが外部の情報源を参照できるようにするための仕組みであり、その核となるのが「ベクトルデータ」を用いた情報変換と検索です。
- ベクトルデータへの変換: RAGは、 自然言語 を、ベクトルデータと呼ばれる 数値の組み合わせ データに変換してデータベースに保存するプロセスです。
- 技術的な位置づけ: この技術自体は、LLMがない時代からすでに存在していた単純な技術です。
RAGの仕組み:エンベディング(埋め込み)による数値化
RAGの仕組みの核は、自然言語を数値データに変換するプロセスにあります。
- 技術名: この言葉を数値に変換する採点や知識を扱う手法は、「 エンベディング 」と呼ばれています。
- 採点プロセスの詳細: この数値化のプロセスは、言葉を多次元空間における座標(点)として表現するために、「採点」を用いて行われます。
- 採点辞書: 全ての言葉を一つ一つ処理するために、採点用の辞書が存在します。
- 採点の付与: 例えば「猫」という言葉であれば、辞書には「人間に対する スコア 」「動物に関する スコア 」など、そのジャンルに関する数千から数万にも及ぶ可能性のある採点(スコアリング)が保存されています。
- データ保存: RAGは、全ての言葉を一つ一つこの採点用の辞書に照らし合わせて全部採点し、その結果の点を保存していきます。
採点し保存したデータから「近いもの」を探索
言葉がベクトルデータとして数値化されると、AIはそれを利用して情報を検索できるようになります。
- 距離の計算: 採点によって保存されたデータ(点)は、多次元空間で表されます。コンピュータは、この点と点との間の 「近い距離」 を計算し、類似性を判断することができます。
- 検索の仕組み: ユーザーが自然言語で情報を要求すると、AIはその要求された言葉と、データベースに保存されている数値化されたデータ(ベクトルデータ)を 照合 し、最も近いところにある言葉を探し出します。
RAGの一時期の流行(2023年12月頃)
RAGは、特にAIの 「幻覚(ハルシネーション)」が騒がれ始めた頃に出てきた解決策の一つとして登場しました。
- 当時の状況: 当時(2023年)、Chat GPTが主要なLLMであった状況において、Chat GPTのLLMはその公開されない性質上、問題点(幻覚など)を抱えていました。そのため、外部情報を補強するRAGが注目を集めました。
AIモデルの進化により騒がれなくなった
RAGが一時的な技術として騒がれなくなった最大の理由は、AIモデル自身の基本的な性能が、COT(Chain of Thought)やHRM(Hierarchical Reasoning Model)といった「思考回路」の発達によって劇的に向上したためです。
- 不要論の発生: この思考回路が強くなるにつれて、AIは命令を一発出すだけで複雑な処理をこなせるようになります。これにより、RAGのように「採点し保存したデータから近いものを探索」するという手順を踏む必要性が低下しました。
- 市場の動き: (RAGのような技術の) 開発意義が薄れた ことが示唆されており、RAGブームが急速に終焉したことがうかがえます。
5. 未来の手法 — バイブコーディング (Vibe Coding)
RAGやエージェントがAIの進化によって「古い技術」となりつつある中、AIの強力な推論能力を前提とした、まったく新しい開発手法「バイブコーディング」が登場しています。
エージェントよりもさらに先進的/最新の手法
バイブコーディングは、現在のAI開発において最も先進的な手法の一つとして位置づけられます。
- 最新のやり方: 本記事では、バイブコーディングを最新の技術として位置づけます。
- エージェントとの比較: 世間では「すごい」と理解され始めたエージェントに対し、「バイブコーディングはエージェントよりもさらに先進的、さらに最新の手法です」と(筆者らは)考えています。
- エージェントの評価: エージェントは、バイブコーディングと比較すると古い技術であると評価されています。
HRMが強いほど未来に力強い手法
この関連性は、HRMがもたらすAIの自律性の向上に起因します。
- 推論力と簡潔さの実現: バイブコーディングは、AIに複雑なワークフローを人間が設定することなく(エージェント開発のように)、AIの強い推論能力に頼って、大まかな指示や方向性を与えるだけで、複雑な結果を得ることを目指します。
- エージェントの不要化: HRMが非常に強力な推論能力を持つと、AI自身が思考(推論)するため、エンジニアが「その前にこういうやり方をしなさい」と指示するエージェントの開発(ワークフロー設定)自体が不要になります。
AIに全て任せる方向性
バイブコーディングは、AIモデルの推論能力が飛躍的に向上した結果、従来の開発者が行っていた複雑な手順設定をAIに完全に任せるという、開発パラダイムの究極的な進化を意味します。
- 推論の必要性: 従来のAI研究の方向性(LLMのみに頼るデータ量増加戦略)は、幻覚(ハルシネーション)の増大という問題に直面しました。
- HRMによる推論の強化: この思考回路の発展がCOTであり、さらにその上に位置する**HRM(Hierarchical Reasoning Model)**という推論が非常に強いモデルが登場しました。
- 自律的な実行: この思考回路が強くなればなるほど、AIは「命令を一発出すだけで、自律的に処理を実行してくれる」ようになります。
人間との接し方・任せ方をリードする段階へ
バイブコーディングが誕生する前提として、AIの基盤モデルの推論能力が飛躍的に向上したことが挙げられます。
人間との接し方・任せ方をリードする段階とは、以下の核心を指します。
- AIへの全委任: モデル自身の水準が強くなる(HRMが強い)ため、「全部AIに任せる」ことが可能になります。
- リードすべき役割: AIが自律的に処理をこなすようになった後、人間が集中すべきことは、 「あとはどういう任せ方、そして人間とどう接するか」 です。
- バイブコーディングの目的: この、AIの強い推論能力を前提として、「どうAIに任せるかをリードする」という手法こそが、バイブコーディングです。
つまり、HRMなどの強力なモデルの登場により、AIが技術的な課題(推論や処理手順の決定)をクリアしたため、人間の役割はプログラミングや手順設定(エージェント)から解放され、AIの能力を引き出し、そのアウトプットを管理・統制する、より高次元な「ディレクション(方向付け)」の役割へとシフトしていくことを、バイブコーディングは象徴しているのです。