1. はじめに:Google BigQueryの迷宮で立ち往生していませんか?
「必要なデータがデータベースのどこにあるかわからない……」
Google BigQueryの膨大なテーブル群を前に、途方に暮れた経験はないでしょうか。特に他業界からITの世界へ飛び込み、十分な教育体制がない現場に派遣された新人エンジニアにとって、これは単なる作業の停滞ではなく、エンジニア生命に関わる死活問題です。
誰かが手取り足取り教えてくれる環境は、今のIT業界ではむしろ稀なケース。自力で目的のデータに辿り着く力は、この業界で生き残るための必須の「サバイバル技術」です。今回は、迷宮から抜け出し、プロとして自立するためのデータ探索術と、現場で重宝されるマインドセットを伝授します。
2. 「探し方」の極意:データベースではなく、まずは「画面(UI)」を見よ
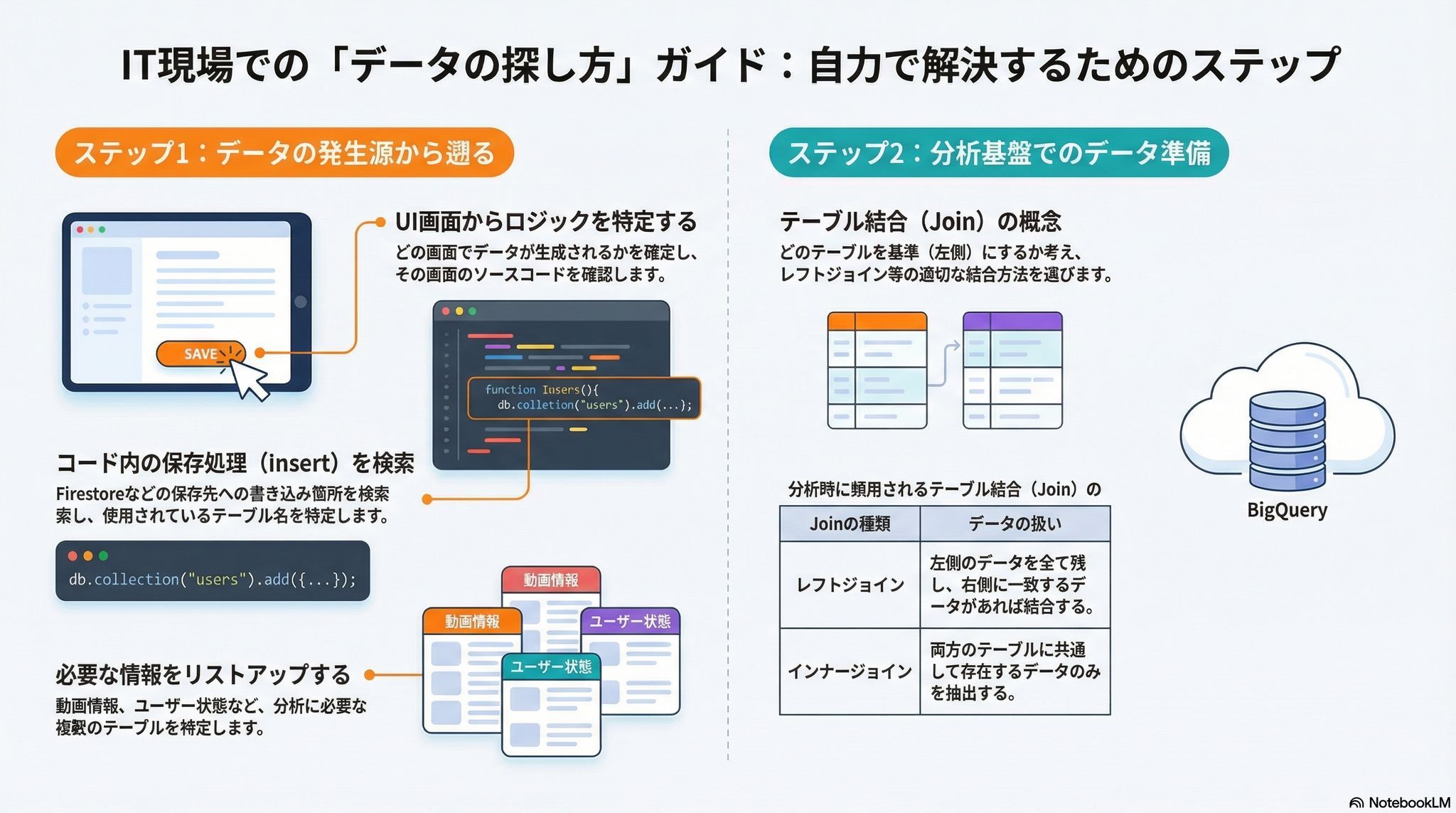
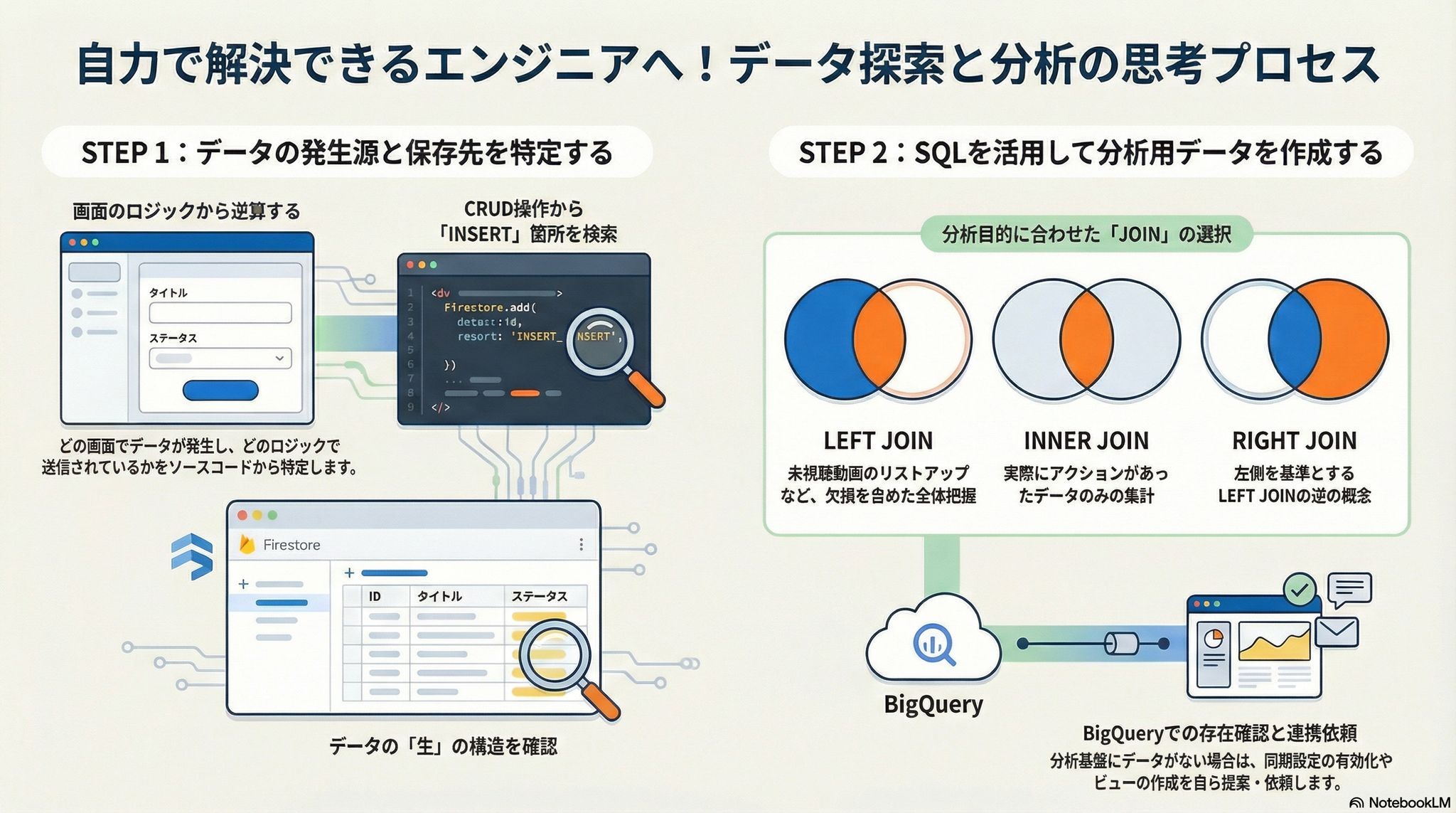
データを探すとき、いきなりSQLを書き始めてはいけません。最も効率的なアプローチは、データベースを直接覗くことではなく、「どの画面でそのデータが発生しているか」を特定し、そこから逆引きすることです。
データのライフサイクルには、登録(Create)、参照(Read)、更新(Update)、削除(Delete)の「CRUD」と呼ばれる4つの基本操作があります。あなたが「参照(SELECT)」したいデータは、必ず世界のどこかで「登録(INSERT)」されています。
メンターが教える「自力で解決するためのロジックフロー」は以下の通りです。
- 画面(UI)を確認する: ユーザーがどのボタンを押し、どの情報が動いているかを把握する。
- アクションを特定する: どの操作によってデータが生成・送信されるかを見極める。
- ソースコードを開く: その機能を制御しているプログラムの場所を突き止める。
- 目的地(DB)を逆引きする: コード内のキーワード(例:Firestoreへの送信処理)で検索し、具体的なインサート先を特定する。
例えば、今回のケースなら「Firestore」という言葉だけで探すのではなく、コードの中から具体的なコレクション名を見つけ出すのがプロのやり方です。
「データが欲しい場合は、データが生成された機能から探す。その中には絶対にどこにインサートするかが書かれている。」
この一歩を踏み出すだけで、あなたは「指示を待つ人」から「システムを解読する人」へと進化します。
3. 「データがない」という事実も立派な成果:BigQueryとFirestoreの落とし穴
必死に調査した結果、「どこにもデータが見当たらない」という結論に至ることがあります。実は、これも立派な調査結果です。
実務では、「Firestoreにはデータが存在するが、BigQueryには同期設定がされていない」 というケースが頻繁に起こります。BigQueryは魔法の箱ではありません。誰かが意図的に設定して初めて、Firestoreのデータが同期されるのです。
探し回っても見つからない場合、単に諦めるのではなく「バックアップ設定や同期バッチが未設定であること」を疑ってください。 これは「ない」ことを確認するという、一歩先を行く高度なアウトプットなのです。
4. SQLの「結合(JOIN)」を直感的に理解する:「引き算」で考える未視聴リスト
データが見つかったら、次は分析です。複数のテーブルを組み合わせる「結合(JOIN)」の概念は、理屈で覚えるよりも「型」として身体に叩き込みましょう。
- Left Join (左結合): FROM句で書いた左側のテーブルを基準にします。右側に一致するデータがあれば合体させ、なければ「NULL(空っぽ)」として残します。
- Right Join (右結合): 右側のテーブルを基準にします。
- Inner Join (内部結合): 両方のテーブルに共通して存在するデータだけを残し、それ以外は切り捨てます。
【メンター直伝:NULLによる引き算ロジック】
- 左側に「公開されている全動画リスト(master_movie_info)」を置く。
- そこへ、右側から「ユーザーの視聴ステータス(master_follower_movie_status)」をレフトジョインする。
- すると、「動画リストには存在するが、視聴ステータスが合致しない(=右側がNULLになる)」行が残る。
この 「全リスト + ユーザー進捗 = NULLが未視聴」 というロジックこそが、SQLを使いこなすための鍵です。
5. 評価を分ける「質問術」:ただの質問を「提案」に変えるテクニック
上司や先輩への報告の仕方は、あなたのエンジニアとしての市場価値を左右します。 「データがどこにあるか分かりません」という丸投げの質問は卒業しましょう。プロフェッショナルは、調査結果に 「提案」 を添えて報告します。
【プロの報告例】 「調査の結果、Firestoreにはこのコレクションが存在していましたが、BigQueryには同期設定がされていないようです。このまま同期設定を追加すべきか、あるいは一時的な対応として手動でViewを作成すべきか、どちらがよろしいでしょうか?」
このように伝えれば、相手は「この新人はシステムの構造を深く理解しているな」と確信し、あなたを「頼れるパートナー」として認識するようになります。
6. おわりに:技術の習得以上に大切なこと
スキルアップを急ぐあまり、自分を追い詰めすぎてはいけません。 現場では、要件が急に変わったり、プロジェクト自体が白紙になったりすることも珍しくありません。せっかく必死に、かつ迅速に作り上げた機能が無駄になってしまう……。そんな激しい変化の中で燃え尽きないためには、「戦略的なペース配分(バランス感覚)」 が重要です。
何でもかんでも最速でこなすのが正解とは限りません。プロジェクトの状況を見極め、あえて「待つ」余裕を持つことも、長く生き残るための知恵なのです。