


ローカルLLMを統合!VibeCodingで実現した次世代AIワークフロー構築
OpenAI Codexの能力を最大限に活用し、ローカルLLMとシームレスに接続する機能が「VibeCoding」によって実現しました。単なる知識や機能の寄せ集めではなく、真に動く、強力な開発ワークフローを構築できたことは大きな成果です。
🌟実現した機能の全体像
今回実装した核となるのは、特定のワークフロー画面(/workflows)に「ローカルAIでAI処理機能」を組み込むことです。この機能群によって、従来のLLM利用の課題を解決し、強力なローカルAI処理パイプラインを構築しました。
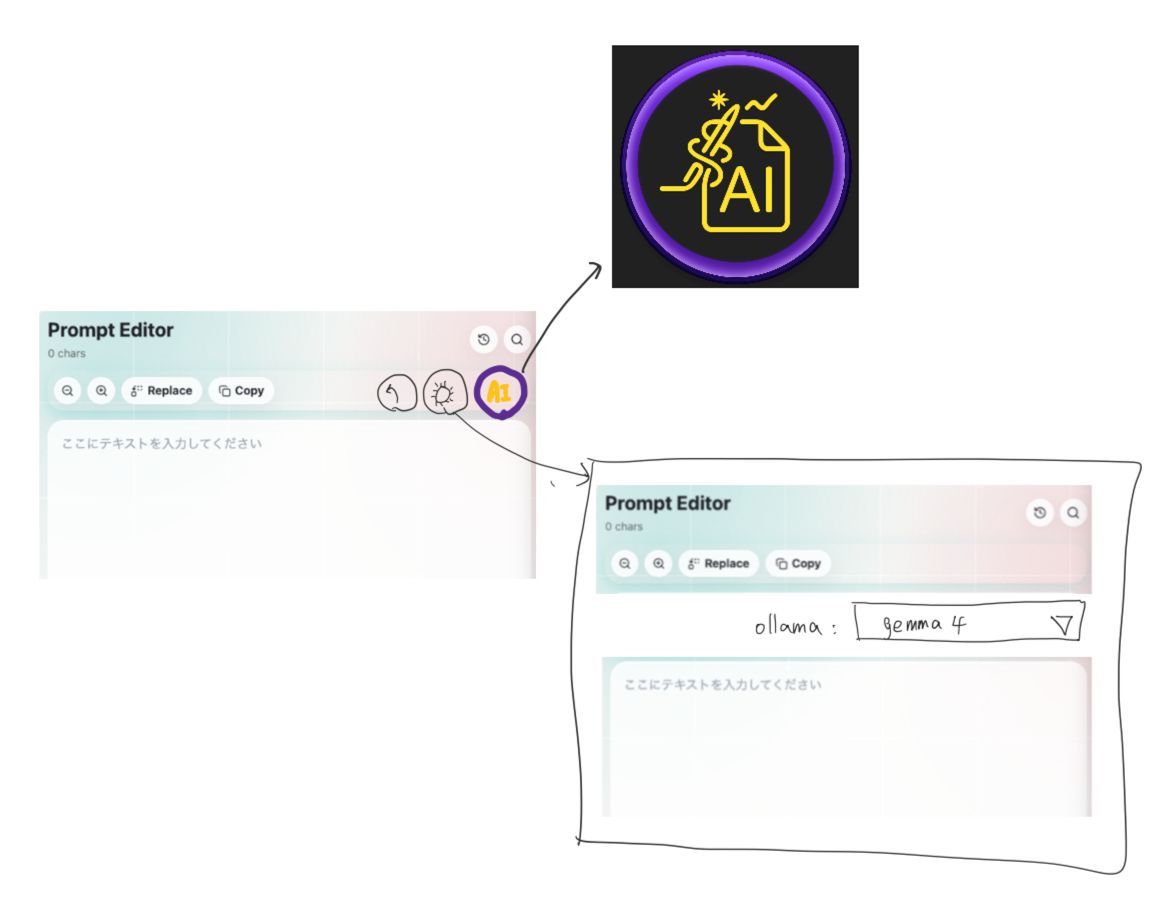
具体的には、以下の3つのボタンを「Copy」の行に右詰で追加しました。
- 前の内容に戻る
- 設定
- ローカルAIで処理
💡ユーザー体験(UX)とロジックの詳細設計
この機能を実現するために、以下のロジックと挙動を設計しました。
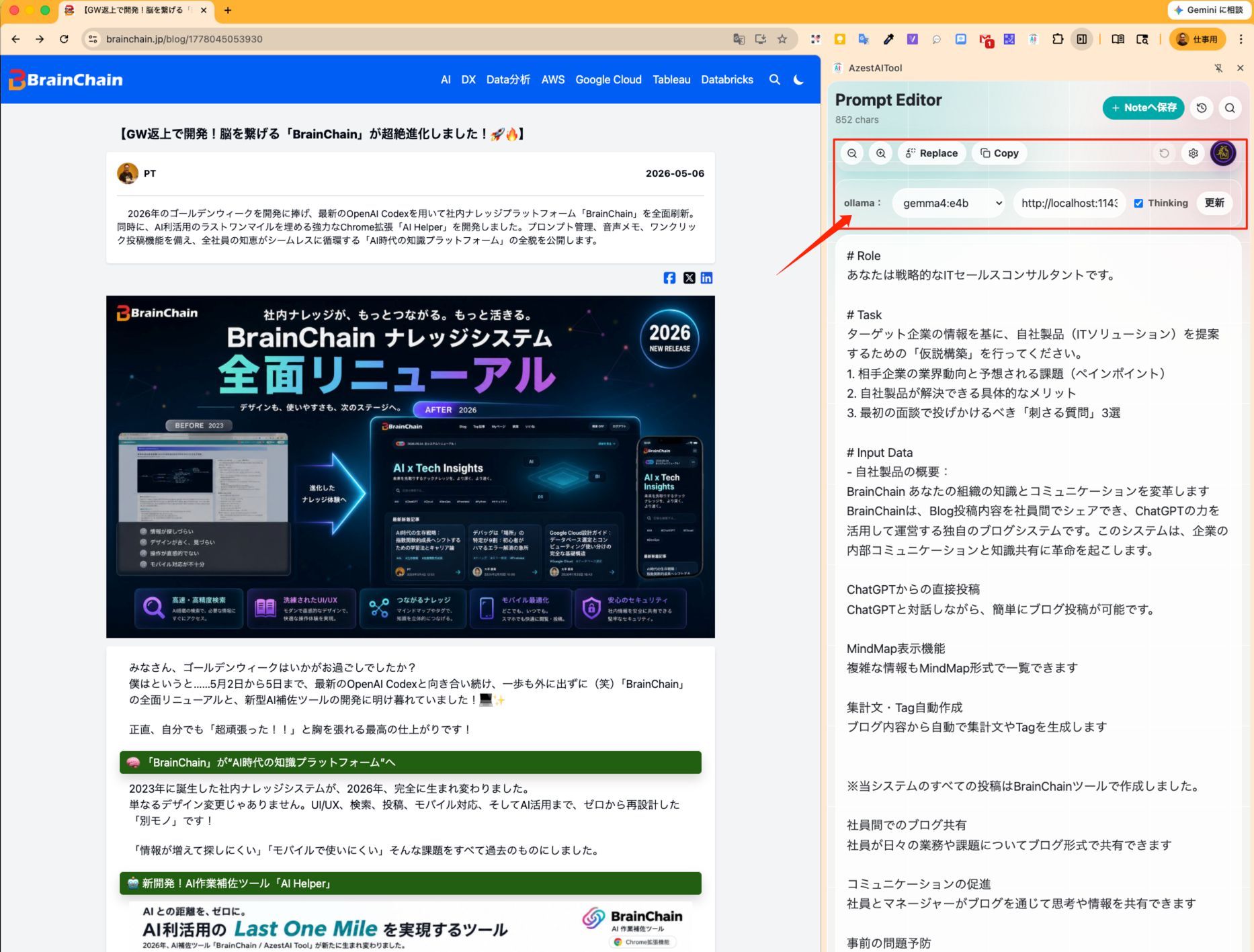
- ローカルAI処理(メイン機能):
- クリック時にポップアップを表示。
- 思考中の場合は「Thinking」タイトルを表示し、OllamaによるThinking内容を表示。
- 思考中でない場合は、「思考中、少々お待ちください。」と表示。
- 処理完了後、ポップアップを閉じ、結果を背後のPrompt欄に自動で挿入します。
- 設定機能:
- インストール済みのOllamaリストを表示します。
- ユーザーが選択したモデル名を
localStorageに記録し、永続的に使用できる状態にします。
- 「前の内容に戻る」機能:
- 標準の
Ctrl/Cmd + Zでは、AI処理後のコンテンツは元に戻せません。 - そのため、履歴に基づき、AI処理前の元のPrompt文を正確に復元し、画面に戻る設計を組み込みました。
- 標準の
✅ OpenAI Codexが問題なく一発完成!(超感動)
今後、文書美化やBlog作文など、ローカルのLLMで使えるようになり、無駄なToken消耗がなく、かつ完全ローカルなので超安全!
⚙️ローカルLLMと外部サーバーを繋ぐための注意点
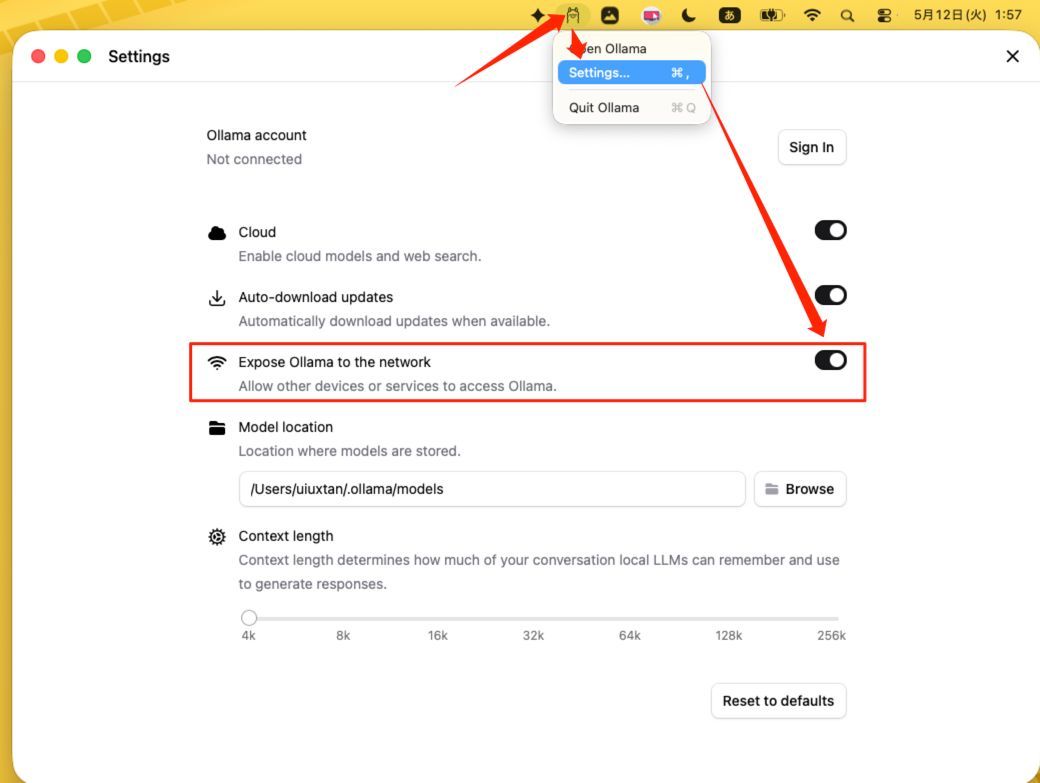
ローカルで動作するOllama環境と、Cloud Runなどでデプロイしたサーバー側のPluginを通信させるためには、ネットワークレベルでの設定が不可欠です。
(Mac環境の例)
1.環境変数設定: ターミナルを開き、以下のコマンドを実行してオリジンを設定します。
launchctl setenv OLLAMA_ORIGINS "*"
2.Ollamaの設定変更: Ollamaの設定画面で「Expose Ollama to the network」をOnに設定します。
3.再起動: Ollamaを一度Quitし、再度起動し直します。
これらの手順を踏むことで、これからのPromptの文書処理は、インターネット上のAPIに頼らずローカルLLM環境で安全かつ迅速に行えるようになりました。API利用料を気にすることなく、高性能な処理が実現できるのは最大のメリットです!
🤖まとめ:ローカルAIがもたらす未来
今回の開発を通じて、ローカル環境の強力なLLM(Ollamaなど)と、カスタムフロントエンドを組み合わせることで、どのような業務ロジックも実現可能だと再認識しました。
最後に、改めて利用しているモデルについて触れておきます。
- 日常的な文書の美化、返信文の生成など、汎用的なタスクにはGemma4:e4bが非常に優秀です。私の開発環境でも非常に軽快に動作します。
- より長文の生成や、複雑な論理処理が必要な場合は、Gemma4:26bを使うと、パフォーマンスの面で抜群の信頼性を発揮します。
ローカルLLMの進化は、開発の可能性を無限に広げてくれています。