


音声自動分割とComfyUI連携!AI動画生成ワークフロー「LTX2.3 V2I」による制作効率化の実装解説
本記事では、開発中の動画制作ツールに導入された「音声アップロード・分割機能」と、ComfyUIを活用した「AI動画生成(LTX2.3 V2I)ワークフロー」の技術的な実装内容について解説します。
これらの機能を組み合わせることで、音声アセットの準備からシーンごとの動画生成までの一連の流れが大幅にスムーズになります。開発の背景から具体的な実装のポイントまでを紹介します。
1. 音声自動分割アップロード機能の実装
背景と課題
動画制作において、音声に合わせてシーンを構成する場合、手動で音声を切り分ける作業は非常に手間がかかります。今回は「9秒」というシーン単位の制約に合わせ、アップロードされた音声を自動で分割・保存する仕組みを構築しました。
解決策と実装のポイント
- AudioUploader.tsxの新設: WAV/MP3のアップロード用インターフェースをヘッダーの制御エリアに追加しました。
- ViteサーバーサイドでのFFmpeg処理:
vite.config.tsにAPIエンドポイントを追加。FFmpegを用いて、音声を9秒間隔のMP3形式に自動分割します。 - データの永続化: 分割されたファイル名は
generated_assets.audioとしてZustand経由でlocalStorageに保存。プロジェクトJSONの書き出し時にもデータが保持されます。 - UIへの反映: 各シーンのカード(MVInfoCard.tsx)に、対応する音声ファイル名と再生コントロールを表示しました。
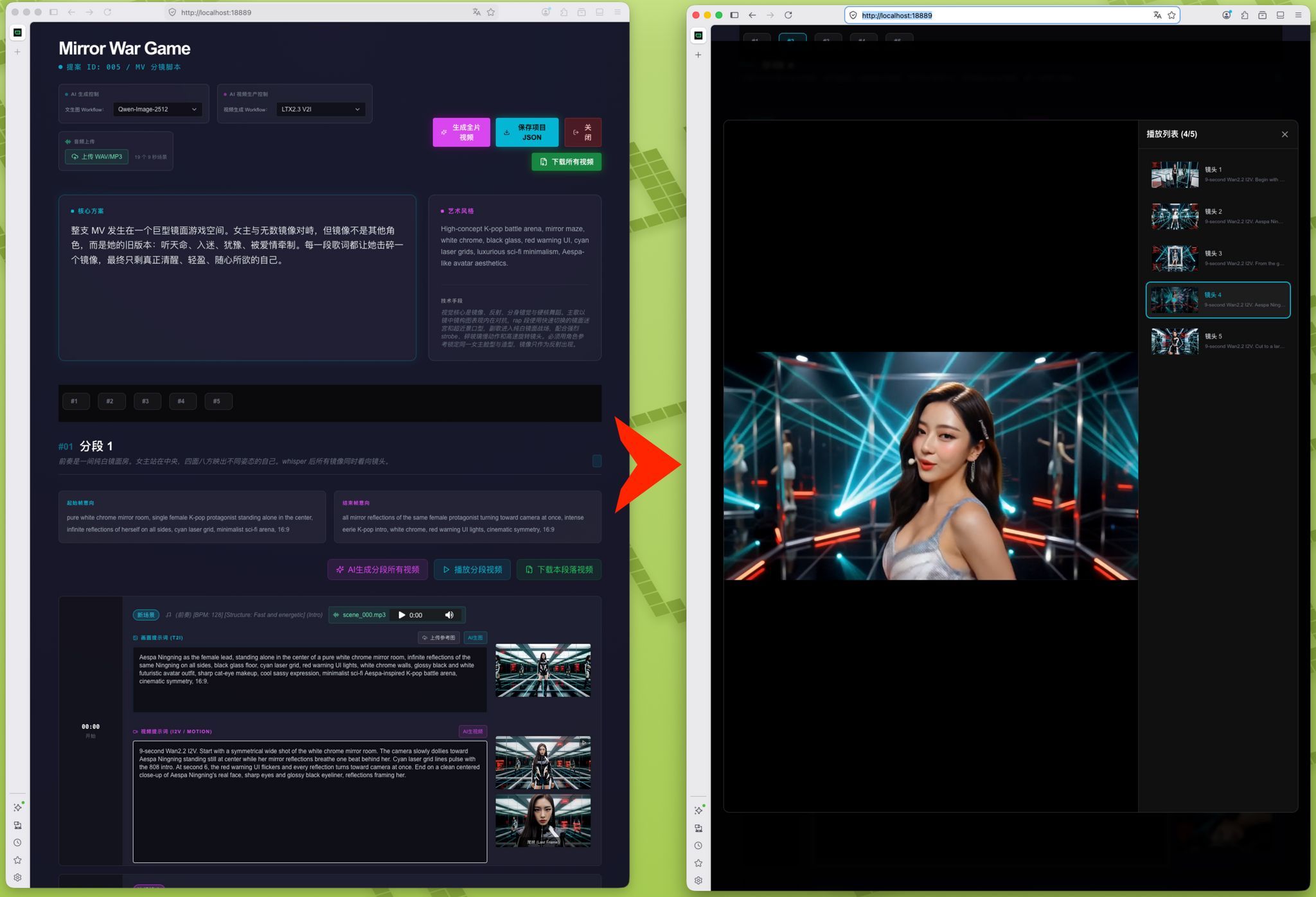
2. AI動画生成「LTX2.3 V2I」の統合
次に、ComfyUIを活用した新しい動画生成ワークフロー「LTX2.3 V2I」をシステムに統合しました。これは「画像」「音声」「プロンプト」の3要素をインプットとする高度な生成フローです。
ワークフローの制御ロジック
提供されたJSONワークフロー(video_ltx2_3_ia2v.json)をベースに、以下のノードへ動的にデータを注入します。
| 入力データ | 対象ノードID | 備考 |
|---|---|---|
| 画像 | 269 | シーンのベース画像 |
| 音声 (MP3) | 276 | 分割済みの9秒音声 |
| プロンプト | 340:319 | テキスト指示 |
| シード値 | 340:285/286 | ランダム生成用 |
3. 一貫性を支える「最終フレーム」の自動抽出
本実装の技術的なハイライトは、生成された動画の「最終フレーム」を自動で抽出するロジックを追加した点です。
- 課題: 元のワークフローには動画保存ノードしかなく、次のシーンへ画像を引き継ぐ(一貫性を保つ)ことが困難でした。
- 対策: 実行時に「SaveImage」ノードを動的に追加。デコードされた画像バッチから最終フレームを取得し、
generated_assets.last_frameとして保存する仕組みを構築しました。
これにより、前のシーンの終わりと次のシーンの始まりを繋ぐ、一貫性のある連続した動画生成が可能になります。
4. 運用・検証結果
今回のアップデートにより、計6ファイルが更新されました。
- 検証状況:
npm run checkおよびnpm run buildは正常にパスしています。 - テスト実績: 20秒のWAVファイルを用いて、3つのMP3セグメントが正しく生成・分割されることを確認済みです。
- 注意事項:
package.json内のjszip/file-saverに関する重複依存の警告がビルド時に発生しますが、これは既存構成に起因するものであり、今回の新機能への影響はありません。
AI生成作品
https://www.youtube.com/watch?v=rWeMx25h94o
まとめ
音声の自動分割と、コンテキスト(最終フレーム)を維持した動画生成フローの実装により、AI動画制作の効率が飛躍的に向上しました。今後はComfyUI環境との接続性をさらに強化し、より複雑なワークフローの統合を目指します。